이번 포스팅에서는 HTTP 버전 별 차이에 대해 알아본다.
↓ HTTP / 0.9 내용
HTTP의 공식 초기 버전으로 TCP/IP 프로토콜을 사용하여 요청 시 서버의 리소스에 대한 경로만 단일 라인으로 요청하는 기능이 제공된다.
(Request)
GET /mypage.html
(Response)
<HTML>
A very simple HTML page
</HTML>메서드 또한 리소스에 대한 요청 GET 만 가능하고 응답 역시 단순하게 파일 내용으로만 구성된다.
HTTP / 1.0
HTTP 1.0 버전에서는 0.9의 제한적인 동작를 개선하기 위해 아래와 같은 기능들이 추가되었다.
- Request Header
- 요청과 응답에 HTTP 헤더가 추가되어 메타데이터를 주고 받음 (프로토콜을 더 유연하고 확장성 있도록 개선)
- Version Field
- 요청과 시작 부분에 버전 정보가 추가
- Status Codes
- 응답 시작 부분에 상태 코드 라인을 추가 (상태 코드 라인을 통해 로컬 캐시를 갱신하거나 사용하는 동작을 수행할수 있음)
- Content Type
- HTTP 헤더의 Content-Type 을 통해 HTML 이외 다른 문서 파일도 통신 가능
- Methods (POST, HEAD)
(Request)
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
(Response)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>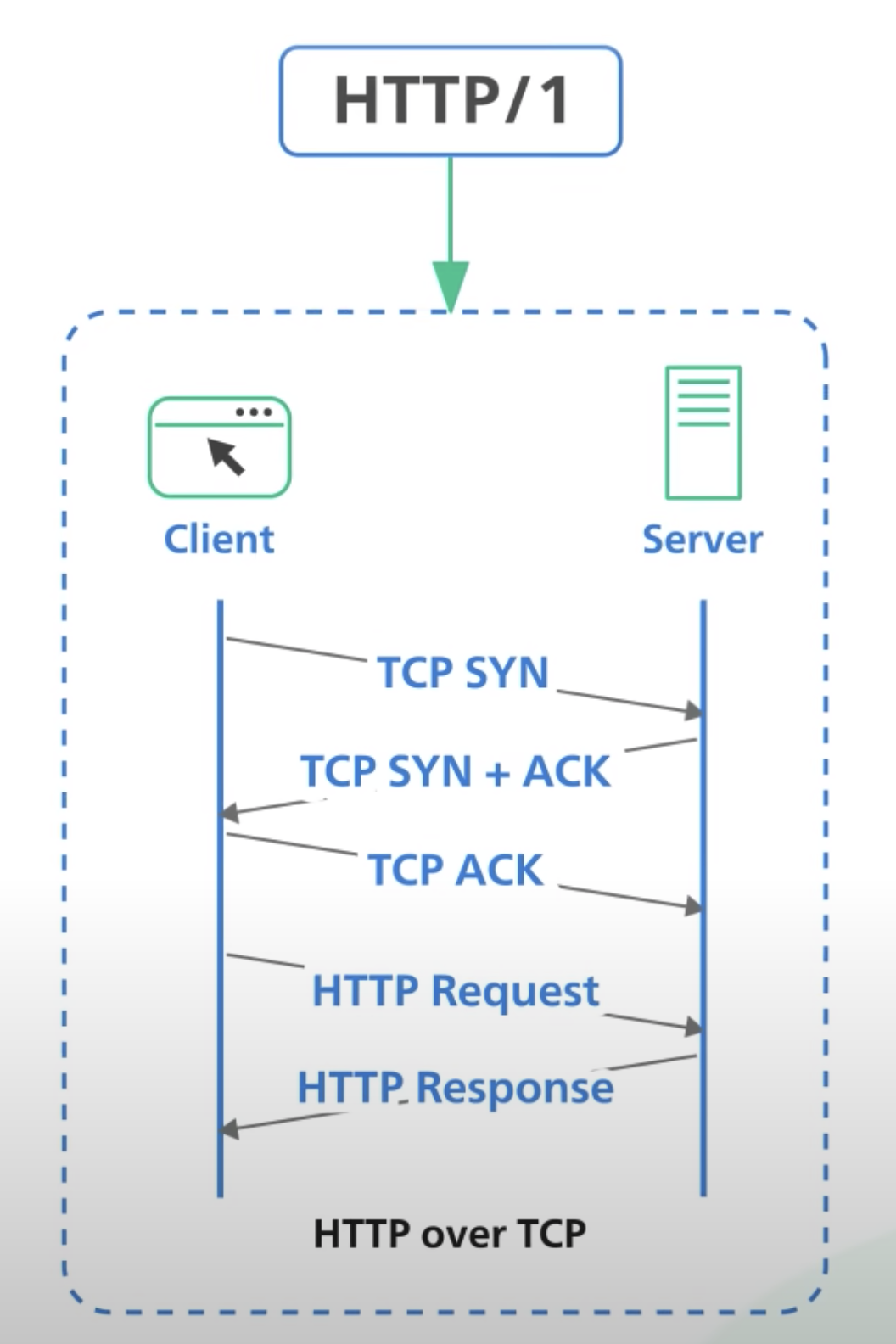
HTTP 1.0 버전의 한계
1.0 버전은 TCP를 사용하여 데이터를 주고 받을 때마다 비효율적으로 TCP 연결, 해제 과정이 이뤄진다.
HTTP / 1.1
HTTP 1.1 은 1999년 공개되어 일반적으로 사용되고 있는 범용적인 버전이다. 1.0 버전에서의 단일 커넥션에 대한 비효율적인 통신과정과 더 다양한 기능을 제공하기 위해 아래 기능들이 추가되었다.
- Host Header
- 1.1 버전에서 추가된 필수 헤더로 동일한 IP에 대해 대상 서버가 복수 도메인 일 때 구분하기 위해 사용
- Persistent Connections
- 1.0 버전에서의 요청 마다 매번 발생하는 불필요한 TCP 연결, 해제 과정 없이 한번의 과정으로 데이터를 주고 받을 수 있음
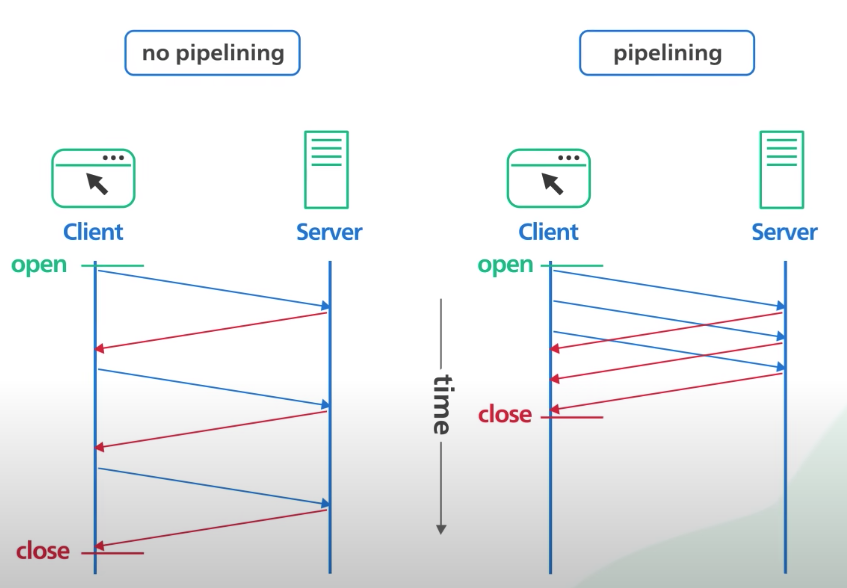
- Pipelining
- 하나의 연결 과정에서 응답을 기다리지 않고 순차적인 요청을 여러번 보낼 수 있음 (hol blocking 발생)
- Methods (PUT, PATCH, DELETE, CONNECT, TRACE, OPTIONS)
(Request)
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
(Response)
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
(content)Persistent connection
이전 버전에서는 요청마다 tcp 연결 과정이 매번 발생하였는데, 매번 3 way handshake, 4 way handshake 가 발생하는 비용을 절감하기 위해 1.1 버전에서는 요청 헤더에 Connetion: Keep-Alive 값을 담아서 timeout 시간 동안에는 연결을 해제하지 않도록하여 tcp 연결을 유지하는 방법을 사용하였다. (참고로 1.1 버전은 기본으로 persistent connection 지원, 1.0 버전에서도 헤더에 Keep-Alive 값을 추가하면 사용 가능)

Pipelining
클라이언트는 한번 보낸 요청에 대한 응답을 기다리지 않고 순차적으로 여러번 요청을 보낼 수 있다. 그에 따라 서버는 순차적으로 요청에 대한 응답을 보내주어 요청과 응답에 대한 지연시간을 줄일 수 있다.
HTTP 1.1 버전의 한계
1. HOL (Head Of Line) Blocking
1.1 버전은 pipelining 을 통해 순차적으로 여러 요청을 서버에 전송할 수 있지만 서버측에서 응답을 순서대로 하나 하나 보내줘야 하기 때문에 가장 처음 보낸 요청에 대한 응답이 느려질 경우 이후 모든 요청에 대해 지연이 발생할 수 있다.
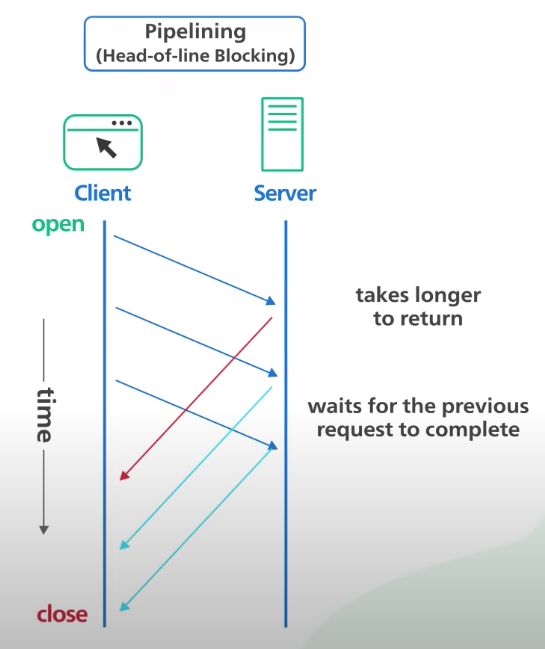
HOL Blocking 의 종류는 다음과 같이 두 종류가 존재한다.
- HTTP HOL Blocking
- TCP HOL Blocking
2. 중복된 헤더 전송
1.1 버전부터 추가된 다양한 헤더 정보들을 매번 중복해서 주고 받기 때문에 매우 비효율적이다.
HTTP / 2.0
HTTP 2.0 은 2015년에 공개되었다. 2.0 버전은 1.1 버전에서 HOL Blocking 과 같은 성능 이슈들을 개선하기 위해 다음의 기능들이 추가되었다.
- Request and Response Multiplexing
- 한번의 연결(세션)로 동시 여러개의 메시지를 응답 순서없이 주고 받을 수 있다.
- Stream Prioritization
- 브라우저에서 리소스 간의 의존관계(우선순위)를 설정할 수 있다.
- Header Compression
- 요청과 응답의 헤더 메타데이터를 HPACK 압축 방식을 통해 압축한다.
- Server Push
- 클라이언트가 별도의 요청 없이 필요 시 서버에서 클라이언트에게 추가적인 리소스를 보낼 수 있다.

HTTP 2.0 버전의 한계
2.0 버전은 이전 버전들의 한계를 개선하였는데 전송 계층인 TCP 프로토콜의 자체적인 한계점으로 인해 tcp hol blocking 을 해결할 수 없다.
HTTP / 3.0
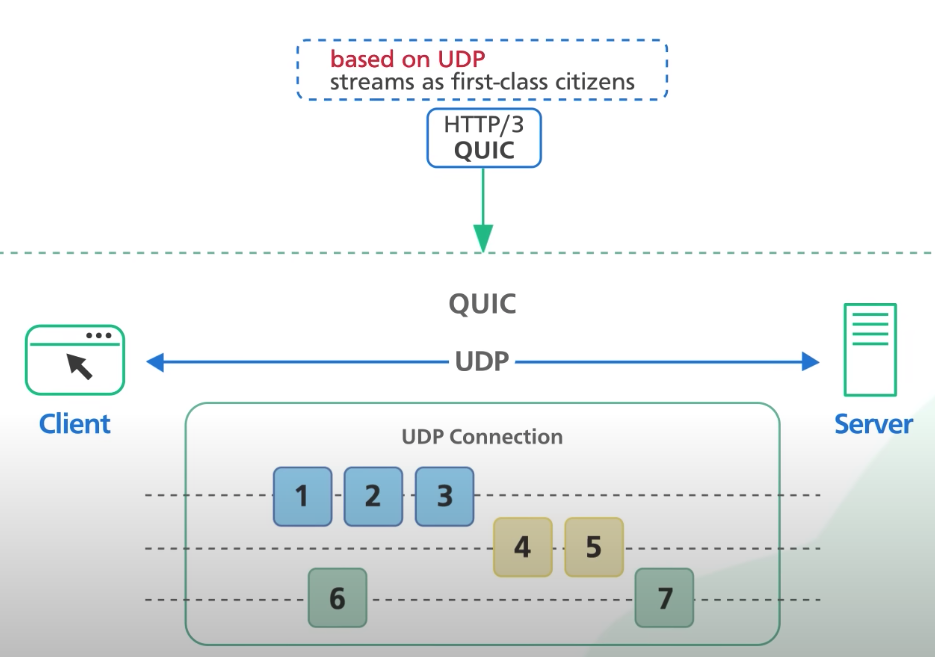
HTTP 3.0 은 2020년도에 공개된 버전으로 가장 최근 공개된 공식 버전이다. 기존 HTTP 프로토콜의 전송 계층인 tcp 의 기능적 한계(tcp hol blocking)를 개선하기 위해 UDP 기반의 QUIC(Quick UDP Internet Connections) 를 사용하였다.
참고 내용
- https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP
- https://www.youtube.com/watch?v=a-sBfyiXysI&t=39s
- https://www.popit.kr/%EB%82%98%EB%A7%8C-%EB%AA%A8%EB%A5%B4%EA%B3%A0-%EC%9E%88%EB%8D%98-http2/
- https://www.baeldung.com/cs/http-versions
- https://www.whatap.io/ko/blog/38/